
Um dos principais recursos do Windows reside no coração do Linux e permite criar shadow copy de seus arquivos!
| Se você apoia nosso site, desative o AdBlock quando visitá-lo, inclusive em Mobile!
Os anúncios são poucos e não invasivos. Se quiser contribuir com nosso trabalho, clique em qualquer banner de sua preferência, exceto dos Parceiros. Mais detalhes clicando aqui.
Introdução
Shadow Copy – ou Shadow Copies, em bom português Cópias de Sombra de Volume – nos termos do mundo da Microsoft®, é o nome de um método de backup nativo no Windows nas versões Workstation, Pro e Server que funciona de forma relativamente simples: Você marca um disco principal para sofrer o backup, e ele faz o backup apenas ‘congelando’ os dados naquele momento tornando-os somente leitura, e guardando as alterações futuras deles “ao lado”, separadamente. É o mesmo processo pra quando você cria um Ponto de Restauração do sistema, só que ele aplica o Shadow Copy no sistema operacional todo e aponta caminhos para retornar seu estado anterior.
Já do lado Linux da força, ele possui um sistema igual, só que pra nós é chamado de Snapshot. O conceito a grosso é o mesmo, você executa o snapshot e o sistema congela os dados naquele ponto. As modificações/novas informações são adicionadas “ao lado” e caso você queira voltar “no tempo”, você consegue ver os dados antigos do momento que o snapshot foi executado. – Por essa razão muitos chamam o COW CopyOnWrite na verdade de RedirectOnWrite, os dados são movidos na escrita.
Mas há diversos poréns:
- A maioria dos sistemas de arquivos comuns não oferece suporte nativo a snapshots: EXT2, EXT3, EXT4, XFS, JFS, exFat e F2FS.
- Por padrão a maioria das distribuições também não vão ofereceram isso, apenas os usuários que encararem a instalação avançada.
- Uma forma de ter snapshots facilmente é utilizando LVM – conforme já abordado aqui em outra publicação – e configurar seu sistema de arquivos por cima; mas também costuma ser uma tarefa pra administradores, espantando usuários comuns que não estão familiarizados com o conceito. Afinal…
No Windows um Shadow Copy pode ser habilitado com 2 cliques por qualquer usuário. E com a mesma facilidade tal qual o Ponto de Restauração do Sistema.
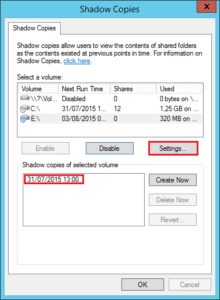
No Linux precisa de mil comandos?
Por que não existe um método simples de faze-lo tal qual o Windows?
Porque o Linux, dentre tantos recursos nativos avançados, requer comandos do terminal pra habilitar. E o caso do Shadow Copy é ainda mais emblemático.
1. Senta, que lá vem história!
Pra maioria dos usuários escolher um método eficiente, confiável e simples de backup de dados não é tarefa fácil especialmente se você usa Linux. Tem N formas de se fazer isso e os comandos mais populares são o rsnapshot, time shift, deja-dup, rclone, rsync, rdiff-backup… E com tantos comandos e possibilidades, você vai se perguntar:
Qual a ideal?
A questão aqui, é que todas que eu citei até permitem criar snapshots dos dados de várias formas, mas todos tem um padrão inadequado: Vão exigir em algum momento uma cópia bruta dos dados para algum lugar, e em cima dessa cópia bruta é que os backups incrementais, os snapshots, ocorrem.
Ou seja, os backups farão o disco ser consumido em dobro antes de que as modificações sejam salvas. Aqueles métodos que não o fizerem, vão consumir processador ou mesmo entrada e saída de dados, gargalos, no disco.
Mas por que não existe pra Linux uma solução absolutamente simples igual a função Shadow Copy, que apenas crie backups dos dados modificações sem cópias brutas de tudo?
Os vilões aqui, são o sistema de arquivos que você usa e principalmente o comando rsync.
2. RSync
O Rsync é uma poderosa ferramenta de backups recheado de recursos, absolutamente popular pela praticidade e ele é o coração de vários outros métodos e ferramentas de backup, seja o rclone, deja-dup, o rdiff-backup e também o rsnapshot. Porém ele não suporta snapshots de forma nativa!
Portanto a maioria dos programas que usam o rsync como base farão cópias brutas dos dados ou utilizar métodos pouco ortodoxos com hardlinks pra criar os backups incrementais.
Hardlink é um segundo caminho para um mesmo arquivo, possuindo o mesmo inodo no disco. Ou seja, de forma bruta o que acontece no arquivo original, refletirá na cópia. Com outros comandos agregados o hardlink pode ser uma forma funcional mas pouco eficiente, pouco adequada de se conseguir criar um snapshot.
2. Sistema de Arquivos
A maioria das distribuições hoje usa EXT4 ou mesmo XFS por padrão porém eles também não suportam shadow copy. Os sistemas de arquivos atuais que suportam shadow copy em sua essência são: BTRFS, ZFS, OpenZFS (Ubuntu) e o gerenciador LVM.
De fato se você fez uma instalação apressada automatizada de seu sistema, possivelmente estará usando EXT4 como base! Não é um problema, afinal ele é sólido, funcional, confiável e já existe a décadas. Mas…. carece de recursos básicos que o NTFS do Windows já possui.
3. Mas e ai?
Bom, a verdade é até simples, como dizem os mais fervorosos do Linux com a filosofia KISS, e pra ter um sistema Linux com cópias de sombra que simplesmente façam backups dos seus dados sem ocupar espaço em disco e que sejam facilmente remanejáveis, você precisará de:
- Sistema de arquivos BTRFS
- Comando CP
- Paciência
- Um ovo de dragão
O ovo de dragão que você encontra em qualquer varejão de sua cidade é pra dar um sabor melhor, opcional.
Feliz, ou infelizmente, você precisará que seu sistema Linux utilize o sistema de arquivos BTRFS, o qual já abordei aqui no site e também uso no meu dia a dia. Principalmente se você utiliza SSD, será beneficiado pela otimização e recursos! Você pode manter a raíz em ext4 e usar BTRFS na /home, ou ainda, criar um disco novo e torná-lo BTRFS.
O Ubuntu – e seus deliciosos sabores – possuem suporte nativo a BTRFS na instalação. Porém na área “avançada”. – A ultima vez que fiz uma publicação sobre a instalação do Ubuntu foi no 18.04, prometo que no 22.04 teremos uma publicação especial! Aguardem.
4. BTRFS
BTRFS habilitado, você precisa estar atento que o BTRFS utiliza o COW – Copy-on-Write – habilitado por padrão, que resumidamente cria “cópias de sombra” dos dados que você copiar. Ou seja, você pode ter uma .ISO de 3Gb, copiar e colar ela na mesma pasta ficando com 2 .ISOs iguais. O BTRFS identifica isso verificando hashs atomicamente, ou seja, a nível de inodes no disco, mapeia os mesmos pontos de dados e simplesmente cria um “atalho” para o original.
Atento que não existe original! Ambos são o mesmo arquivo válido em disco, pode apagar o primeiro ou o segundo que ele continuará íntegro, mas o espaço em disco consumido é apenas se fosse 1 cópia dele.
As alterações nesse arquivo serão remanejadas para um novo local e só as mudanças ficarão salvas, ocupando bem menos espaço em disco do que iria.
5. CP
Para ter a shadow copy funcional, você precisará do comando CP, nativo de todas as distribuições. É basicamente um comando de cópias de arquivos que utiliza outra metologia, diferente do rsync.
Porém, o CP possui vários parâmetros e um deles é o –reflink, que cria um link de referencia ao inodo do dado no disco, ou seja, você cria uma cópia real que aponta pra outro setor, salvando apenas as alterações! Pode apagar o original, que o “novo” continuará íntegro.
O principal método de uso do CP, com esse parâmetro, é:
$ cp --reflink "/caminho/de/origem" "/caminho/de/destino"
Atentos: Se o sistema de arquivos não for BTRFS ou ZFS, o CP dará erros dizendo que o sistema de arquivos não suporta reflinks!
O CP também contempla os seguintes parâmetros:
- –force
Permite criar um backup no alvo que tenha o mesmo nome da origem! Assim os dados apesar de diferentes poderão ter o mesmo nome. - –backup=numbered
Aplica um sistema “backup” simples: Cria cópias dos dados mas renomeando eles para ~1~, ~2~ e assim sucessivamente.
Esses arquivos recebem um bit especial para ficarem ocultos no sistema de arquivos! - –reflink
O propriamente método de snapshots com BTRFS - -R
Para pastas cheias de outras pastas e arquivos.
Reunindo tudo, temos um comando assim:
$ cp --force --backup=numbered --reflink -R "/caminho/de/origem" "/caminho/de/destino"
Atento: Se origem for escrito como “origem”, a pasta ORIGEM será copiada integralmente!
Se utilizar “origem/”, com a barra, o conteúdo de origem será copiado. Mesma estrutura de comando do rsync.
Atentos: O comando acima não copia pastas iniciadas com . ! Ou seja, .config, .wine etc não sofrem backup.
Para isso crie um comando separado e mude -R para -a.
Você pode abrir um terminal paralelo, com o comando “watch” para monitorar o consumo de disco em tempo real com:
$ watch df -h
E observar seu espaço atual.
Faça N cópias de uma .ISO pesada, de 2 ou 3 Gb, usando o comando cp acima! Note que você terá 10, 20 cópias, mas o consumo em disco continuará o mesmo.
Você pode repetir o processo com documentos, imagens, PDFs, etc. E poderá alterar trechos desses documentos e repetir o comando CP; terá cópias originais antigas, antes das alterações, e cópias novas, pós alterações. E o consumo em disco será mínimo, ideal também para usar em HDs mecânicos, poupando o I/O de dados iguais.
6. Acesso
A essa altura você me pergunta: Como acessar os dados, se estão ocultos?
Pelo terminal, um “ls” basta para revelar sua existência. E para torna-los visíveis para os gerenciadores de arquivos, use:
$ mv "/caminho/do/backup/pasta_oculta~1~" "/novo/caminho/do/backup/pasta"
O comando mv permite apenas renomear um arquivo enquanto move ele de lugar; E remova o ~1~ do nome desse arquivo!
Assim ele surgirá para ser acessado. E não, isso não fará ele ocupar espaço em disco, apenas ficará visível.
7. Deleção
Para complementar, você deve ter um sistema “simples” que apague os dados mais antigos, para não acumular dezenas de backups!
Para isso, os seguintes comandos são pertinentes:
Para arquivos:
$ find "/caminho/do/backup" -type f -mtime +5 -delete
Para diretórios:
$ find "/caminho/do/backup" -type d -mtime +5 -exec rm -rf {} \;
Assim, o comando vai procurar arquivos ou pastas que sejam mais velhos que 5 dias!
Alterando 5 para 30 você fará os backups perdurarem 1 mês comercial antes que sejam apagados pelo comando.
8. Cron
Para completar, una os comandos cp e find no cron para ter um sistema automático de shadow copy de seus diretórios que também apaga automaticamente o que for mais antigo!
Já explicamos como o cron funciona aqui!
9. FAQ
Apenas uma observação pertinente, falaremos sobre metadados a seguir. Ao contrário dos dados normais dos usuários, metadados são informações como a tabela de partição, os volumes e subvolumes do BTRFS, caminhos de dados apontados por reflinks de backups gerados, caminhos de snapshots de subvolumes e outras informações que normalmente só ficam á mostra para o sistema operacional.
- Por que não usar Snapshots de subvolumes em vez de reflinks?
Por vezes você vai desejar backups apenas de alguma pasta ou arquivo, enquanto que um snapshot contempla todo um subvolume.
Além disso, não há um consenso dos desenvolvedores mas estipula-se, baseado em relatos e experiências vistas em fóruns, de que um sistema não pode ter mais do que 20 snapshots, ou ele ficará muito fragmentado, tornando-o demasiadamente lento, inoperável. Snapshots manipulam índices de subvolumes, gerando mais metadados escritos no disco. – O recomendável é que os snapshots sejam feitos apenas quando necessário, em uma atualização de sistema como um ponto de restauração permitindo recupera-lo caso algo dê errado. E logo que concluir, apague o snapshot anterior para manter o subvolume “saudável”.
Enquanto que, com reflinks, apenas os metadados dos arquivos ganham novos caminhos, preservando a estrutura dos subvolumes do BTRFS.
- Mas esse backup não vai lotar o sistema? Não vai ficar lento? Como o sistema cuida disso?
Eu fiz um teste pessoal aqui, primeiro observei como estava o sistema de arquivos no atual momento, com o comando “sudo btrfs fi usage /” e anotei os valores. Na publicação dedicada ao BTRFS expliquei um pouco mais na sessão 7. Troubleshooting.
Executei esse “backup” na minha HOME toda, várias vezes:
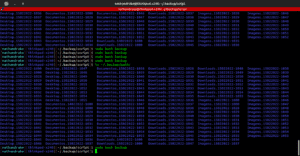
Os dados em “device unallocated” e “Free (estimated)” estavam iguais. Nada foi alterado, não houve consumo de disco com os reflinks! Porém, o valor de METADADOS que era 1Gb começou a aumentar consideravelmente a cada novo backup. De 1 Gb disponível, logo chegou a 900Mb usados!
Com as versões mais novas do BTRFS, essa gestão é automática, portanto logo o valor de METADADOS foi expandido para 2 Gb, conforme a imagem:
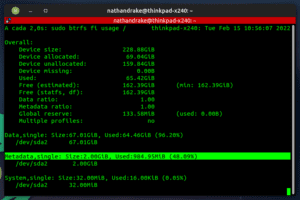
Enquanto você mantiver o sistema com manutenção em dia – digamos, balance semanal ou mensal – e tiver espaço livre de unallocated data pra operar, os metadados serão expandidos á medida que o disco for enchendo de novos backups com reflink.
Isso ocorre porque o valor real de metadados pode ser pequeno, em média 1 Gb para 100 Gb, 10 Gb para 1 Tb. Se você fizer muitos reflinks, esse valor pode chegar a 20, 30 Gb sob os mesmos 1 Tb. E por padrão o BTRFS não aloca esse espaço todo porque nem todo mundo precisa disso.
Lembre-se: Uma vez que há espaço alocado para metadados, esse espaço apenas infla, aumenta, ele nunca diminui! Depois de terminados os testes eu apaguei todo o conteúdo do backup feito, retornando os metadados a 400Mb mais ou menos, porém o limite continua o novo valor de 2 Gb.
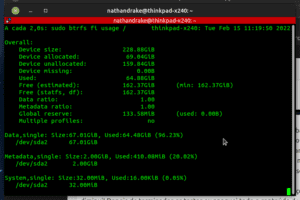
Ou seja, atento se você for utilizar reflinks, perderá um pouco do espaço útil de dados para usar mais espaço para metadados. Mas esse espaço não é tão absurdo, mesmo em 2 Tb será de até 20Gb, aproximadamente.
Semelhante ao que ocorre com snapshots, excessivos backups com reflinks podem deixar o sistema mais lento. Porém, a tolerância, pela natureza da operação, é maior, digamos que de aproximadamente 100 backups de sua /home são necessários para começar a tornar o sistema lento. Inoperável acima dos 200 – coisa que eu duvido muito que você chegue nesse valor!
10. Conclusão
Com o tutorial de hoje você deliberadamente terá uma shadow copy funcional no linux, prático, com pouco consumo de disco e excelente desempenho, por consumir pouca CPU e pouco I/O de disco para funcionar.
Infelizmente não é uma solução pronta, com uma interface de usuário – como várias coisas no linux – mas aqui o intuito maior é que funcione e seja confiável para ser usado em produção, seja ela doméstica ou empresarial.
$urbancompasspony
Autodidata, me aprofundei em sistemas operacionais baseados em UNIX®, principalmente Linux. Também procuro trazer assuntos correlacionados direta ou indiretamente, como automação, robótica e embarcados.