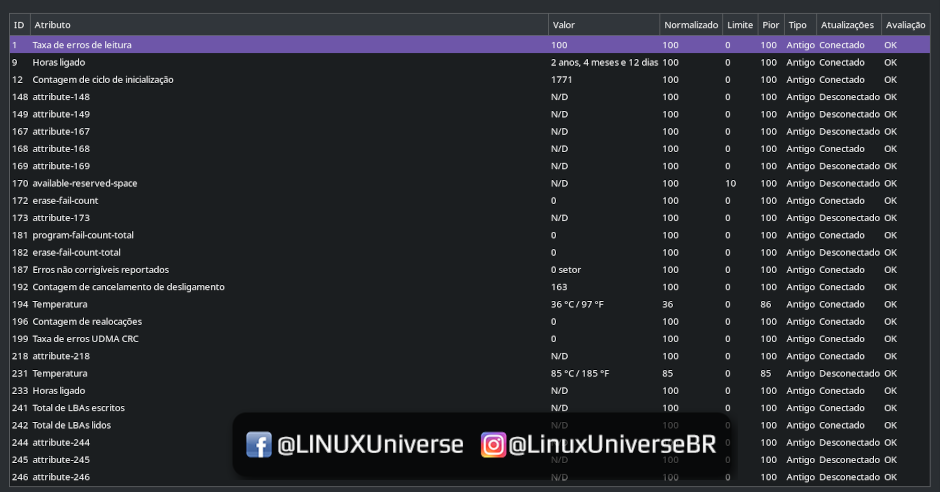
O que é SMART de um HDD, SSD ou NVMe? Pra que serve? Como avaliar a saúde do meu dispositivo de armazenamento? Aprenda hoje!
| Se você apoia nosso site, desative o AdBlock quando visitá-lo, inclusive em Mobile!
Os anúncios são poucos e não invasivos. Se quiser contribuir com nosso trabalho, clique em qualquer banner de sua preferência, exceto dos Parceiros. Mais detalhes clicando aqui.
1. Introdução
VOCÊ jovem – ou nem tanto – da internet que está lendo esta publicação de um computador, provavelmente o está fazendo utilizando um HDD (Hard Drive Disk), um SSD (Solid State Drive) ou um NVMe (N… V…. deve ser alguma coisa).
Estes dispositivos de armazenamento tão comuns da informática possuem tecnologias para verificação de erros internos que de forma geral são chamados de SMART ou S.M.A.R.T. .
2. SMART
O SMART – Self-Monitoring, Analysis, and Reporting Technology, ou no bom português: Tecnologia de Auto-Monitoramento, Análise e Relatório – é uma tecnologia que de forma sintética é uma pequena firmware, um software que executa no nível mais baixo do dispositivo de armazenamento monitorando a saúde do mesmo. Ou seja, o HDD, SSD ou mesmo o NVMe sabem quando estão próximos de falhar e podem também, a depender do sistema operacional em uso, te alertar quando estão falhando.
Esse relatório é especial pelo seguinte: Ele é escrito pelo “usuário” do dispositivo de armazenamento, porém fica somente-leitura para o resto do sistema. Os valores aumentam, mas nunca diminuem, semelhante ao hodômetro de um carro; e quanto maior os valores, maior a tendência de falhas do dispositivo.
E como eu acesso isso no meu sistema Linux?
O Gnome Disk Utility costuma ter um menu para exibir tabelas SMART, porém há serviços via terminal como o smartctl adicionado com a aplicação smartmontools, e o skdump, que este, de forma mais direta, lê a tabela SMART e a exibe ao usuário.
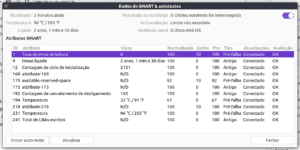
O comando skdump é basicamente este:
$ sudo skdump /dev/sdX
sendo X a letra do seu dispositivo.
Caso seu sistema não tenha o Gnome Disk Utility ou ainda o skdump, instale-os do repositório da sua distribuição.
Não vou entrar em detalhes absolutamente técnicos porque aqui não cabe saber as nuances de como o SMART opera, mas sim entender o que são seus atributos.
3. Atributos
Cada fabricante sejam elas a Toshiba, WD, Seagate e Kingston, por exemplo, possuem a implantação do padrão de tabela SMART em seus dispositivos, porém, cada uma pode ou não adotar alguns parâmetros que serão exibidos.
Mas de consenso geral, os parâmetro mais comuns que estas tabelas exibem são:
- Raw read error rate
Taxa de erros de leitura – Depende do contexto. - Spin up time
Tempo que o disco girou desde que foi ligado pela primeira vez. - Start/stop count
Quantas vezes o dispositivo passou por um ciclo de ligar e desligar. - Reallocated sector count
Este aqui é perigoso, comentarei mais abaixo! - Seek error rate
Taxa de erros encontrados de forma geral no dispositivo. - Power on hours count
Tempo que o dispositivo trabalhou, em horas, desde que rodou a primeira vez.
Ou seja, se contabilizar 800 horas então ele já tem mais ou menos 1 mês de “trabalho”
Somando todas horas, as vezes em que esteve ligado. - Spin retry count
Vezes em que a cabeça de leitura do HDD voltou para a base inicial após alguma falha mecânica, geralmente picos de energia ou falhas de cabeamento SATA. - Recalibration retry count
Vezes em que a cabeça de leitura foi recalibrada. - Power cycle count
Contagem de vezes que o dispositivo passou por um ciclo completo de ligar e desligar.
Se ligou, rodou por 1 hora e desligou, conta como 1 ciclo. - Reallocation event count
Quantas vezes um bloco do armazenamento foi realocado por falha mecânica. - Current pending sector count (bad block)
Este aqui é ABSOLUTAMENTE GRAVE e merece um tópico próprio! - Uncorrectable sector count
Setores sem correção detectados. - CRC error count
Depende da fabricante, em geral erros de firmware do dispositivo. - Write error count
Erros de escrita no disco, por quaisquer motivos. - Command Timeout
Quantas vezes, por algum motivo, o dispositivo perdeu conexão com o computador via SATA.
Geralmente quedas de energia ou uma fonte ruim podem causar isso.
Sendo que, alguns dispositivos como SSD’s podem ter mais parâmetros – como a vida útil dos transístores por exemplo – enquanto que os HDD’s são os que tem menos parâmetros.
O que complica a análise de um SMART para o grande público está o fato de que os parâmetros todos devem ser avaliados e interpretados em conjunto. Ou seja, não é por quê uma linha exibiu um valor alto de erros, que o dispositivo esteja necessariamente apresentando defeitos. Porém 1 deles pode ser observado imediatamente:
4. Bad Blocks
Quando um dispositivo apresenta uma falha de hardware irrecuperável, o setor aonde os dados ficavam armazenados sofrem um problema chamado BAD BLOCK, ou bloco ruim, ou seja, ali não é mais possível gravar ou ler qualquer informação. Para a maioria dos casos, um badblock significa que o dispositivo está perdendo informações e, se ele surge numa partição do sistema operacional, ele vai apresentar alguma falha grave como um kernel panic; se surgir numa pasta de usuário, algum arquivo que ali estiver presente vai desaparecer ou apresentar um erro genérico de entrada/saída.
Na tabela SMART, os parâmetros mais importantes são:
- Current pending sector count (bad block)
A contagem atual de badblocks que o disco apresenta. Quanto mais alto o valor, mais é imperativa que ocorra a troca desse dispositivo, ou você começará a testemunhar corrupções de dados e/ou perda de arquivos. - Uncorrectable sector count
Costuma ser o mesmo valor do Current pending sector, a quantidade de setores que não puderam ser corrigidos. - Reallocated sector count
Setores realocados. Em raros casos, pode ter o mesmo valor de Current pending sector, indicando que apesar do badblock, aquele setor foi mudado de lugar e os dados que haviam ali não se perderam.
Todo dispositivo de armazenamento possui uma quantidade bem limitada de setores que podem acomodar realocações, valores baixos na ordem de 50 a 200. Raramente se atinge o pico antes que a quantidade de Current pending sectors aumente o suficiente para extrapolar o valor.
De qualquer modo, quaisquer valores acima de 0 que existirem para os itens 1 e 2 sem correspondência no item 3, o dispositivo de armazenamento deve ser substituído com celeridade!
5. E os demais parâmetros?
Os demais parâmetros que merecem destaque são:
- Raw read error rate
Taxa de erros de leitura – Depende do contexto. - Seek error rate
Taxa de erros encontrados de forma geral no dispositivo. - CRC error count
Depende da fabricante, em geral erros de firmware do dispositivo. - Command Timeout
Quantas vezes, por algum motivo, o dispositivo perdeu conexão com o computador via SATA.
Geralmente quedas de energia ou uma fonte ruim podem causar isso. - End to end error
Erros que ocorreram entre o computador e o dispositivo, não necessariamente por falhas no cabeamento.
E estes dois:
- Hardware ECC Recovered
- UDMA CRC Error count
Que são erros que podem ocorrer na firmware do dispositivo – como uma BIOS que há dentro do HDD, SSD, NVMe…
Estes parâmetros se estiverem muito altos costumam significar, de forma resumida
- Alguma falha de cabeamento
- Qualquer falha de comunicação da firmware do disco com o computador
- Erro genérico de que apesar do cabeamento estar Ok, houve um erro em que os dados que entraram diferem dos dados de saída e vice-versa. Provavelmente erros da controladora, processador (do dispositivo!) ou cache de dados do dispositivo.
- Comunicação da firmware do dispositivo para com os alvos de escrita (os pratos dos HDDS, ou os chips que receberão os dados nos SSD’s/NVMe’s)
- Erros de comunicação da cabeça de leitura dos HDD’s ou erros da ponte que comunica os dados ao computador em SSD’s.
- Entre outros.
Mas por quê estes erros, que soam graves, não são tão importantes? Porque em 99.999% dos casos os dispositivos de armazenamento conseguem corrigir estes erros e funcionar sem perdas de dados!
Mas e aquele 0.001%?
Há um erro de comunicação “bizarro” em que você estava acessando seus arquivos e de repente tudo sumiu de um minuto para outro e o computador não consegue ler mais o dispositivo.
Os demais parâmetros indicam tempo de funcionamento, quantas vezes o dispositivo ligou, etc. Eles não são fundamentalmente úteis, diria mais pra informar quando um dispositivo deve ser trocado, afinal se um HDD beira os 6 anos de uso… ele já está fazendo hora extra dependendo da carga de trabalho!
6. Conjunto da Obra
Lembram que eu comentei que o conjunto da obra é quem define o real status do disco? Vamos a alguns exemplos práticos:
Exemplo 1
Eu tenho um HDD que apresentou estes dados SMART:
- Raw read error rate 2368907346
- Reallocated sector count 0
- Seek error rate 2368907346
- Spin retry count 57
- Recalibration retry count 0
- Reallocation event count 0
- Current pending sector count 0 (bad block)
- Uncorrectable sector count 34
- CRC error count 56
- Write error count 40
- Command Timeout 0
Os valores dos parâmetros 1 e 3 estão altos e iguais. Vou ignorá-los porque há outros parâmetros que podem ter provocado eles. Já os valores dos parâmetros 8 a 10 estão baixos mas presentes, o HDD já passou por erros mas se recuperou.
VEREDITO: O HDD ainda pode ser usado, porém tenha consciência de que ele poderá estar um pouco mais lento que o normal.
Exemplo 2
Eu tenho um HDD que apresentou estes dados SMART:
- Raw read error rate 23689
- Reallocated sector count 0
- Seek error rate 23689
- Spin retry count 30
- Recalibration retry count 0
- Reallocation event count 1
- Current pending sector count 2 (bad block)
- Uncorrectable sector count 2
- CRC error count 0
- Write error count 2
- Command Timeout 2
Temos 2 command timouts, 2 uncorrectable sectors e 2 current pending sectors; provavelmente 2 quedas de energia e 2 corrompimentos do dispositivo. Porém em Reallocation event, só 1 foi realocado. Ou seja, uma queda de fato causou um dano ao dispositivo e 1 setor se perdeu!
VEREDITO: O HDD ainda pode ser usado, porém tenha consciência de que ele não está funcionando perfeitamente como deveria e, apesar de não apresentar lentidão, ele já apresenta 1 bad block que pode ser o primeiro de vários para um curto ou médio prazos.
Exemplo 3
Eu tenho um HDD que apresentou estes dados SMART:
- Raw read error rate 236
- Reallocated sector count 0
- Seek error rate 23
- Spin retry count 30
- Recalibration retry count 0
- Reallocation event count 2477
- Current pending sector count 5953 (bad block)
- Uncorrectable sector count 3476
- CRC error count 0
- Write error count 0
- Command Timeout 924
Houveram muitas quedas de energia que danificaram o dispositivo. Porém ele apresentou um dano permanente, que depois trouxe novos erros “por conta própria”, aumentando a quantidade de bad blocks em absurdos 5953 (mesmo que 2477 foram corrigidos).
VEREDITO: Trocar o disco imediatamente, sob o sério risco de perda de dados!
7. SSD’s e NVMe’s
Estes costumam ter uma tabela SMART diferenciada com alguns parâmetros mais completos como:
- Available Spare: 100%
- Available Spare Threshold: 10%
- Percentage Used: 40%
- Data Units Read: 33.191.321 [16,9 TB]
- Data Units Written: 82.512.667 [42,2 TB]
- Host Read Commands: 448.453.976
- Host Write Commands: 2.344.306.368
Devido à natureza do armazenamento, os dispositivos de armazenamento de estado sólido em geral conseguem contabilizar uma série de dados precisos, como quantos Tb ou Pb de dados já foram gravados no total desde a primeira vez que foi ligado; ou ainda a porcentagem de saúde do dispositivo e quanto resta até que ele apresente um defeito e pare de funcionar.
SSD’s e NMVe’s costumam ficar em modo somente-leitura quando apresentam alguma falha muito grave que impeça seu funcionamento adequado. Isso ocorre como último recurso, antes dele parar de vez e os dados se perderem permanentemente. Devido a isso, os dispositivos de armazenamento sólido em geral, estatisticamente, são mais confiáveis que os HDD’s por terem um modo de acesso especial mesmo após um defeito grave.
8. Tabela completa
A tabela SMART completa pode ser encontrada nos sites das principais fabricantes como a Kingston. Por ser algo praticamente interpretativo, eu recomendo fortemente que leia as descrições e dicas das fabricantes do seu dispositivo, pra se familiarizar com todos os parâmetros; e observar o SMART dos seus dispositivos periodicamente para ter uma proximidade maior do quanto restam de vida.
No caso específico de dispositivos externos, eu fiz uma publicação separada aqui que explica como acessá-los principalmente no Linux que há especificidades!
9. Conclusão
Apesar de ser complexo à primeira vista…. e continuar complexo na terceira vista, lá pela quinta você se familiariza e a leitura de uma tabela SMART não soará tão absurda quanto aparenta! Se tiver a oportunidade de ver o status SMART de uma dezena de computadores de diferentes épocas e idades notará alguns padrões de comportamento e valores da tabela.
Também seria interessante observar de dispositivos que conhecidamente estão problemáticos, como o HDD externo daquele seu tio distante que desapareceu depois de uma polêmica ceia de Natal do final de 2019… – Isso foi muito específico.
Aproveitando o desabafo, as piores marcas que trabalhei com certeza são WD e Seagate dos lotes rotulados nas cores azuis e verdes, por serem dispositivos de entrada de baixa qualidade. Isso também vale para os SSD’s e NVMe’s das duas marcas!

Façam o teste: Peguem um novo lacrado em alguma loja, se rodar o dump de SMART deles, provavelmente verá vários ERROS reportados nele! De fábrica! Dispositivos de linhas REFURBISHED – remanufaturados – também podem apresentar erros no SMART que estão dentro dos padrões aceitáveis pela indústria.
A recomendação que faço, atualmente, para HDD’s são os da Toshiba por serem simples baratos e resilientes, enquanto que nos SSD’s a Kingston e a ADATA não decepcionaram. (ainda!)
Algumas fontes:
Experiências Pessoais
TecDicas
Wikipedia
Autodidata, me aprofundei em sistemas operacionais baseados em UNIX®, principalmente Linux. Também procuro trazer assuntos correlacionados direta ou indiretamente, como automação, robótica e embarcados.
Excelentes dicas,nao devemos vacilar com os dados no hd pois pode ser fatal em materia de perdas.